Analyse Toetsen op representativiteit
Bij schatten en toetsen worden uitspraken over populatiegegevens gedaan op basis van steekproefuitkomsten. Het kan zijn dat de samenstelling van de respondenten erg afwijkt van de samenstelling van de populatie. Als groepen die onder- of oververtegenwoordigd zijn een andere mening hebben dan de rest van de respondenten kan de schatting of toets verkeerde antwoorden geven.
Het doel van toetsen op representativiteit is om te onderzoeken of de samenstelling van de respons afwijkt van de samenstelling van de populatie. Dit op relevante kenmerken. Wat relevant is hangt af van waarover uitspraken worden gedaan en wie tot de populatie behoren. Als respons niet representatief is kan via Data, Weight Cases een aangepaste analyse worden gedaan (voorbeeld).
Bij het toetsen op representativiteit wordt overigens de chikwadraattoets gebruikt.
Heel gebruikelijke hypothesen zijn hier:
H0: De respons is representatief voor kenmerk X
H1: De respons is niet representatief voor kenmerk X
Toetsen op representativiteit is als volgt uitgewerkt:
- Voorbeeld
- Uitwerking in SPSS
- Het resultaat
- Opmerkingen naar aanleiding van de resultaten
- In toetstermen
- Het gebruikte databestand
- Uitwerking in SPSS, methode twee

Voorbeeld
In de gemeente Gennep is een winkelier benieuwd naar de naamsbekendheid van zijn winkel in de gemeente Gennep. Het percentage van de naamsbekendheid moet gelden voor de hele gemeente Gennep.
De gemeente Gennep bestaat uit de vijf kernen: Gennep, Ottersum, Milsbeek, Heijen en Ven-Zelderheide. Als alleen inwoners uit de kern Gennep bevraagd worden is het aannemelijk dat de naamsbekendheid verkeerd geschat wordt. Wellicht dat er ook andere kenmerken meespelen. Die worden nu even buiten beschouwing gelaten.
Om de representativiteit te kunnen toetsen moet de verdeling van de inwoners over de vijf kernen bekend zijn. De website van de gemeente Gennep levert de volgende info (stand 1 januari 2019):
| Dorp | Inwoneraantal | % |
| Gennep | 9.192 | 54 |
| Heijen | 2.045 | 12 |
| Milsbeek | 2.769 | 16 |
| Ottersum | 2.259 | 13 |
| Ven-Zelderheide | 807 | 5 |
| Totaal | 17.072 | 100 |
Uitwerking in SPSS
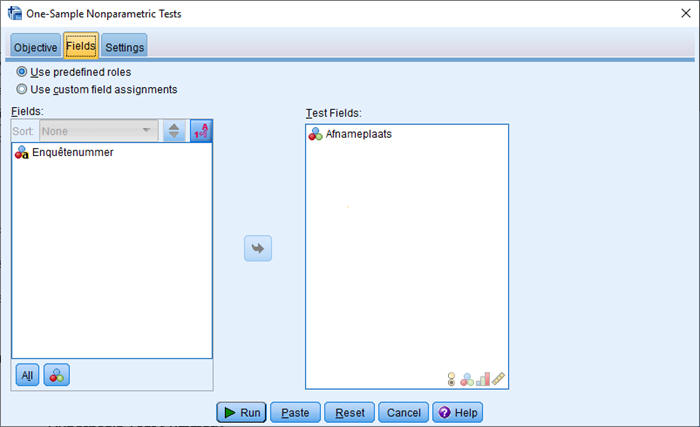
In het bijbehorende databestand is een kolom met woonplaats van de respondent opgenomen. Hiermee kan nu getoetst worden op representativiteit. Dat gaat als volgt:
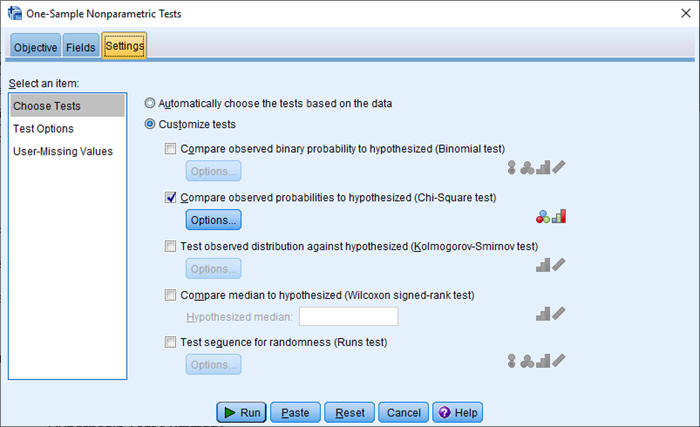
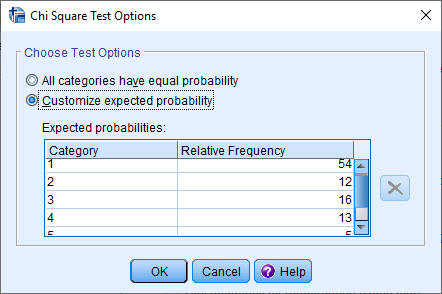
Vul dan het scherm als volgt in:
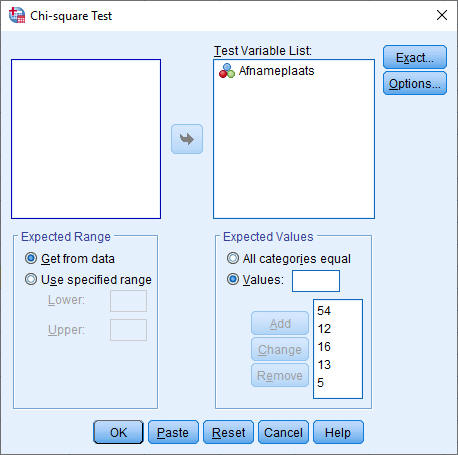
Drie opmerkingen hierbij:
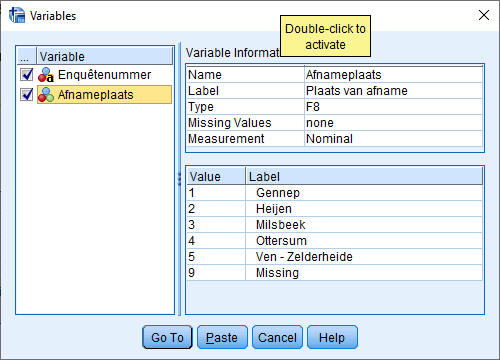
- Het invullen van de waardes komt heel specifiek: de volgorde van de in te vullen Values is de volgorde van de values van Afnameplaats (zie in de figuur hieronder).
- In plaats van de percentages hadden ook de echte inwoneraantallen ingevuld kunnen worden.
- De toets is ook te bereken via Nonparametric Tests --> One Sample. De uitwerking ervan staat onderaan op de pagina.
Het resultaat is:
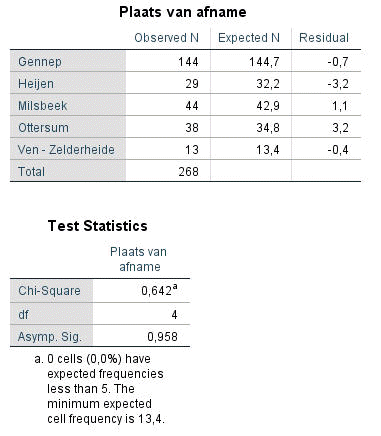
Opmerkingen naar aanleiding van de resultaten:
- De waargenomen aantallen liggen erg dicht bij de verwachte aantallen.
- 0,0 % van de cellen heeft een verwachte waarde lager dan 5. Dat mag voor het toepassen van de cjikwadraatttoets maximaal 20% zijn, dus oké.
- Het minimum van de verwachte aantallen is 13,4. Dat moet 1 of hoger zijn bij het toepassen van de chikwadraattoets, dus oké.
- De asymptotische significantie is 0,958. Erg hoog. Kennelijk heeft men bij het afnemen van de vragenlijst er al voor gezorgd dat de respons representatief is naar dorpskern. Misschien door een quotasteekproef te doen.
In toetstermen:
H0: De respons is representatief naar herkomst uit de
dorpskernen
H1: De respons is niet representatief naar herkomst uit de
dorpskernen
Aan de voorwaarden voor de chikwadraattoets is voldaan.
De significantie = 0,958. Deze is groter dan 0,05. Bij een betrouwbaarheid van 95 % wordt H0 geaccepteerd en is de steekproef representatief naar herkomst uit de dorpskernen (α = 5 %).
Uitwerking in SPSS, methode twee